Vytvoříme jednoduchou třívrstvou neuronovou síť pro klasifikaci datové sady MNIST.
TensorFlow od Googlu je v poslední době žhavým tématem hlubokého učení. Software s otevřeným zdrojovým kódem, navržený tak, aby umožňoval efektivní výpočet grafů toku dat, je zvláště vhodný pro úkoly hlubokého učení. Je navržen tak, aby byl spouštěn na jednom nebo více CPU a GPU, což z něj činí dobrou volbu pro komplexní úkoly hlubokého učení. Ve své nejnovější inkarnaci – verzi 1.0 – ji lze dokonce spustit na určitých mobilních operačních systémech. Tento úvodní tutoriál k TensorFlow poskytne přehled některých základních konceptů TensorFlow v Pythonu. Budou dobrým odrazovým můstkem k budování složitějších sítí hlubokého učení, jako jsou konvoluční neuronové sítě, modely přirozeného jazyka a rekurentní neuronové sítě v balíčku. Vytvoříme jednoduchou třívrstvou neuronovou síť pro klasifikaci datové sady MNIST. Tento výukový program předpokládá, že jste obeznámeni se základy neuronových sítí, s nimiž se můžete v případě potřeby seznámit ve výukovém programu o neuronových sítích. Chcete-li nainstalovat TensorFlow, postupujte podle pokynů zde. Až budete hotovi, můžete se také podívat na knihovnu hlubokého učení vyšší úrovně, která se nachází nad TensorFlow s názvem Keras.
Nejprve se podívejme na hlavní myšlenky TensorFlow.
1.0 grafy TensorFlow
TensorFlow je založen na výpočtu založeném na grafu – „co to proboha je?“, dalo by se říct. Je to alternativní způsob konceptualizace matematických výpočtů. Zvažte následující výraz; $ a = (b + c) * (c + 2) $. Tuto funkci můžeme rozdělit do následujících částí:
$$ \begin{align} d &= b + c \\ e &= c + 2 \\ a &= d * e \end{align} $$
Nyní můžeme tyto operace znázornit graficky jako:
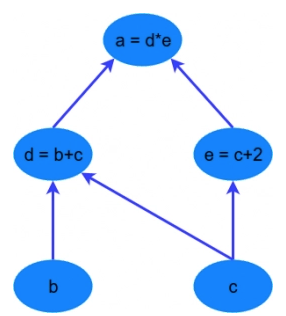 Jednoduchý výpočtový graf
Jednoduchý výpočtový graf
Může se to zdát jako hloupý příklad – ale všimněte si silné myšlenky při vyjádření rovnice tímto způsobem: dva z výpočtů $ d=b+c $ a $ e=c+2 $ lze provádět paralelně. Rozdělením těchto výpočtů mezi CPU nebo GPU nám to může přinést značné zisky ve výpočetních časech. Tyto zisky jsou nutností pro aplikace velkých dat a hluboké učení – zejména pro komplikované architektury neuronových sítí, jako jsou konvoluční neuronové sítě (CNN) a rekurentní neuronové sítě (RNN). Myšlenkou TensorFlow je schopnost vytvářet tyto výpočtové grafy v kódu a umožnit výrazné zlepšení výkonu prostřednictvím paralelních operací a další zvýšení efektivity.
Níže se můžeme podívat na podobný graf v TensorFlow, který ukazuje výpočtový graf třívrstvé neuronové sítě.
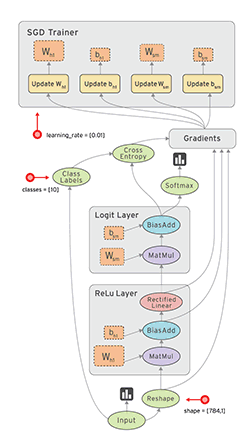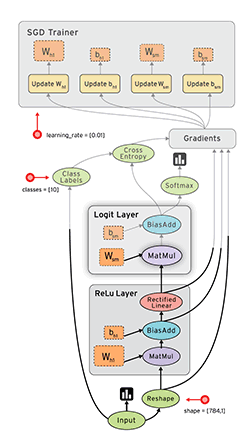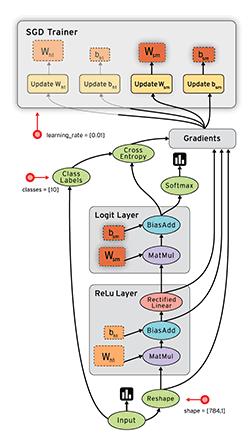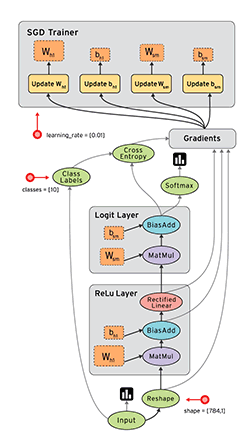
Animované datové toky mezi různými uzly v grafu jsou tenzory , což jsou vícerozměrná datová pole. Tenzor vstupních dat může být například 5000 x 64 x 1, což představuje vstupní vrstvu se 64 uzly s 5000 trénovacími vzorky. Za vstupní vrstvou následuje skrytá vrstva s rektifikovanými lineárními jednotkami jako aktivační funkcí. Existuje konečná výstupní vrstva (ve výše uvedeném grafu nazývaná „logitová vrstva“), která využívá křížovou entropii jako funkci nákladů/ztrát. V každém bodě vidíme příslušné tenzory proudící do bloku „Gradients“, který nakonec proudí do optimalizátoru Stochastic Gradient Descent, který provádí zpětné šíření a klesání gradientu.
Zde můžeme vidět, jak lze použít výpočetní grafy k reprezentaci výpočtů v neuronových sítích, a v tom samozřejmě TensorFlow vyniká. Podívejme se, jak provádět některé základní matematické operace v TensorFlow, abychom získali představu, jak to celé funguje.
2.0 Jednoduchý příklad TensorFlow
Jak tedy můžeme přimět TensorFlow provést výše uvedený malý příklad výpočtu – $ a = (b + c) * (c + 2) $? Nejprve je potřeba zavést proměnné TensorFlow. Níže uvedený kód ukazuje, jak deklarovat tyto objekty:
import tensorflow as tf
# create TensorFlow variables
const = tf.Variable(2.0, name="const")
b = tf.Variable(2.0, name='b')
c = tf.Variable(1.0, name='c')Jak je vidět výše, proměnné TensorFlow lze deklarovat pomocí funkce tf.Variable . První argument je hodnota, která má být proměnné přiřazena. Druhým je volitelný řetězec názvu, který lze použít k označení konstanty/proměnné – to se hodí, když chcete provádět vizualizace. TensorFlow odvodí typ proměnné z inicializované hodnoty, ale lze ji také explicitně nastavit pomocí volitelného argumentu dtype. TensorFlow má mnoho vlastních typů jako tf.float32, tf.int32 atd.
Objekty přiřazené k proměnným Pythonu jsou ve skutečnosti tenzory TensorFlow. Poté se chovají jako normální objekty Pythonu – proto, pokud chcete získat přístup k tenzorům, musíte mít přehled o proměnných Pythonu. V předchozích verzích TensorFlow existovaly globální metody přístupu k tenzorům a operacím na základě jejich názvů. To už neplatí.
Chcete-li prozkoumat tenzory uložené v proměnných Pythonu, jednoduše je zavolejte jako normální proměnnou Pythonu. Pokud to uděláme pro proměnnou „const“, uvidíte následující výstup:
<tf.variable 'const:0'="" shape="()" dtype="float32," numpy="2.0">
Tento výstup vám poskytuje několik různých informací – zaprvé je to jméno 'const:0', které bylo přiřazeno tenzoru. Dále je datový typ, v tomto případě typ TensorFlow float 32. Nakonec je tu „numpy“ hodnota. Proměnné TensorFlow v TensorFlow 2 lze snadno převést na numpy objekty. Numpy je zkratka pro Numerical Python a je klíčovou knihovnou pro vědu o datech Pythonu a strojové učení. Pokud neznáte Numpy, co to je a jak jej používat, podívejte se na tyto stránky. Příkaz pro přístup k numpy formě tenzoru je jednoduše .numpy() – použití této metody bude ukázáno brzy.
Dále se vytvoří některé výpočetní operace:
# now create some operations
d = tf.add(b, c, name='d')
e = tf.add(c, const, name='e')
a = tf.multiply(d, e, name='a')Všimněte si, že d a e jsou po provedení operací automaticky převedeny na hodnoty tenzoru. TensorFlow má k dispozici velké množství výpočtových operací pro provádění nejrůznějších interakcí mezi tenzory, jak zjistíte, když budete postupovat touto knihou. Účel výše zobrazených operací je zcela zřejmý a konkretizují operace b + c, c + 2.0 a d * e. Tyto operace jsou však nepraktickým způsobem, jak dělat věci v TensorFlow 2. Operace níže jsou ekvivalentní těm výše:
d = b + c
e = c + 2
a = d * ePro přístup k hodnotě proměnné a lze použít metodu .numpy() , jak je uvedeno níže:
print( f”Proměnná a je {a.numpy()}” )
Výpočtový graf pro tento jednoduchý příklad lze vizualizovat pomocí funkce TensorBoard, která je součástí TensorFlow. Toto je skvělá vizualizační funkce. Takto vypadá graf v TensorBoard:
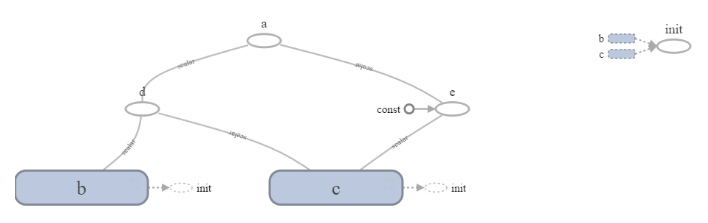
Jednoduchý graf TensorFlow
Větší dva vrcholy nebo uzly, b a c, odpovídají proměnným. Menší uzly odpovídají operacím a hrany mezi vrcholy jsou skalární hodnoty vycházející z proměnných a operací.
Výše uvedený příklad je triviální příklad – jak by to vypadalo, kdyby existovalo pole hodnot b , ze kterého by se vypočítalo pole ekvivalentních hodnot a ? Proměnné TensorFlow lze snadno vytvořit pomocí numpy proměnných, jako jsou následující:
b = tf.Variable(np.arange(0, 10), name='b')Volání b zobrazí následující:
<tf.proměnná 'b:0'="" shape="(10,)" dtype="int32," numpy="array([0," 1,="" 2,="" 3,="" 4,="" 5,="" 6,="" 7,="" 8,="" 9])=""></tf.proměnná>
Všimněte si, že numpy hodnota tenzoru je pole. Protože proměnná numpy předaná během vytváření instance je rozsah hodnot int32, nemůžeme ji přidat přímo do c , protože c je typu float32. Proto je třeba nejprve použít operaci tf.cast, která mění typ tenzoru:
d = tf.cast(b, tf.float32) + cSpuštění zbývajících předchozích operací s použitím nového b tensoru dává následující hodnotu pro a :
Proměnná a je [ 3. 6. 9. 12. 15. 18. 21. 24. 27. 30.]
V numpy může vývojář přímo přistupovat k řezům nebo jednotlivým indexům pole a přímo měnit jejich hodnoty. Lze totéž udělat v TensorFlow 2? Lze přistupovat k jednotlivým indexům a/nebo řezům a měnit je? Odpověď je ano, ale ne tak přímočará jako v numpy. Například, pokud b bylo jednoduché numpy pole, dalo by se snadno provést následující b[1] = 10 – to by změnilo hodnotu druhého prvku v poli na celé číslo 10.
b[1].assign(10)To pak projde do podobného tvaru:
Proměnná a je [ 3. 33. 9. 12. 15. 18. 21. 24. 27. 30.]
Vývojář by také mohl spustit následující, aby přiřadil část hodnot b :
b[6:9].assign([10, 10, 10])Nový tenzor lze také vytvořit pomocí zápisu řezu:
f = b[2:5]Vysvětlení a výše uvedený kód vám ukazují, jak provádět některé základní manipulace a operace s tenzory. V části níže bude uveden příklad, kdy je neuronová síť vytvořena pomocí paradigmatu Eager v TensorFlow 2. Ukáže, jak vytvořit trénovací smyčku, provést dopředný průchod neuronovou sítí a vypočítat a aplikovat gradienty na optimalizační metoda.
3.0 Příklad neuronové sítě
V této části je demonstrována jednoduchá třívrstvá neuronová síť postavená v TensorFlow. V následujících kapitolách jsou popsány složitější struktury neuronových sítí, jako jsou konvoluční neuronové sítě a rekurentní neuronové sítě. Pro tento příklad to však bude jednoduché.
V tomto příkladu bude použita datová sada MNIST, která je zabalena jako součást instalace TensorFlow. Tato datová sada MNIST je sada obrázků ve stupních šedi 28×28 pixelů, které představují ručně psané číslice. Má 60 000 tréninkových řádků, 10 000 testovacích řádků a 5 000 ověřovacích řádků. Jedná se o velmi běžnou základní datovou sadu pro klasifikaci obrázků, která se používá ve strojovém učení.
Data lze načíst spuštěním následujícího:
from tensorflow.keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()Jak lze pozorovat, zavaděč dat Keras MNIST vrací pythonovské n-tice odpovídající trénovací a testovací sadě (Keras je další rámec hlubokého učení, nyní úzce integrovaný s TensorFlow, jak bylo zmíněno dříve). Velikosti dat výše definovaných n-tic jsou:
- x_train: (60 000 x 28 x 28)
- y_train: (60 000)
- x_test: (10 000 x 28 x 28)
- y_test: (10 000)
Data x jsou informace o obrázku – 60 000 obrázků o velikosti 28 x 28 pixelů v tréninkové sadě. Obrázky jsou ve stupních šedi (tj. černobílé) s maximálními hodnotami určujícími intenzitu bílých 255. Data x bude třeba upravit tak, aby se nacházela mezi 0 a 1, protože to zlepšuje efektivitu tréninku. Data y jsou odpovídající štítky obrázků – označující, jaká číslice je na obrázku zobrazena. To bude potřeba převést do „one-hot“ formátu.
Při použití standardní, kategorické funkce ztráty zkřížené entropie (toto bude ukázáno později), je při trénování klasifikačních úloh vyžadován jeden hotový formát, protože výstupní vrstva neuronové sítě bude mít stejný počet uzlů jako celkový počet možných klasifikačních štítků. Výstupní uzel s nejvyšší hodnotou je považován za předpověď pro toto odpovídající označení. Například v úloze MNIST existuje 10 možných klasifikačních štítků – 0 až 9. V každé neuronové síti tedy bude 10 výstupních uzlů vykonávajících tuto klasifikační úlohu. Pokud máme příklad výstupního vektoru [0,01, 0,8, 0,25, 0,05, 0,10, 0,27, 0,55, 0,32, 0,11, 0,09], maximální hodnota je na druhé pozici / výstupní uzel, a proto to odpovídá číslici „ 1“.
Tato konverze se snadno provádí v TensorFlow, jak bude brzy ukázáno, když bude pokryta hlavní tréninková smyčka.
Poslední věcí, kterou je třeba zvážit, je, jak extrahovat trénovací data v dávkách vzorků. Níže uvedená funkce to zvládne:
def get_batch(x_data, y_data, batch_size):
idxs = np.random.randint(0, len(y_data), batch_size)
return x_data[idxs,:,:], y_data[idxs]Jak lze pozorovat ve výše uvedeném kódu, data, která mají být dávkována, tj. data x a y , jsou předávána této funkci spolu s velikostí dávky. První řádek funkce generuje náhodný vektor celých čísel s náhodnými hodnotami mezi 0 a délkou dat předávaných funkci. Počet vygenerovaných náhodných celých čísel se rovná velikosti dávky. Poté jsou vrácena data x a y , ale návratová data jsou pouze pro vybrané náhodné indexy. Všimněte si, že se to provádí na objektech numpy array – jak bude zanedlouho ukázáno, převod z numpy polí na objekty tensor bude prováděn „za běhu“ v rámci trénovací smyčky.
Existuje také požadavek na ztrátovou funkci a dopřednou funkci, ale ty budou brzy pokryty.
# Python optimisation variables
epochs = 10
batch_size = 100
# normalize the input images by dividing by 255.0
x_train = x_train / 255.0
x_test = x_test / 255.0
# convert x_test to tensor to pass through model (train data will be converted to
# tensors on the fly)
x_test = tf.Variable(x_test)Nejprve se vytvoří počet epoch tréninku a velikost dávky – všimněte si, že se jedná o jednoduché proměnné Pythonu, nikoli proměnné TensorFlow. Dále jsou vstupní trénovací a testovací data, x_train a x_test , škálována tak, aby jejich hodnoty byly mezi 0 a 1. Vstupní data by měla být vždy škálována při trénování neuronových sítí, protože velké, nekontrolované vstupy mohou výrazně ovlivnit trénovací proces. Nakonec jsou vstupní data testu x_test převedena na tenzor. Náhodný dávkový proces pro trénovací data se nejsnáze provádí pomocí numpy objektů a funkcí. Testovací data však nebudou v tomto příkladu dávkována, takže celá sada vstupních testovacích dat x_test je převedena na tenzor.
Dalším krokem je nastavení proměnných váhy a zkreslení pro třívrstvou neuronovou síť. Vždy existuje L – 1 počet vah/tenzorů předpětí, kde L je počet vrstev. Tyto proměnné jsou definovány v kódu níže:
# now declare the weights connecting the input to the hidden layer
W1 = tf.Variable(tf.random.normal([784, 300], stddev=0.03), name='W1')
b1 = tf.Variable(tf.random.normal([300]), name='b1')
# and the weights connecting the hidden layer to the output layer
W2 = tf.Variable(tf.random.normal([300, 10], stddev=0.03), name='W2')
b2 = tf.Variable(tf.random.normal([10]), name='b2')Proměnné váhy a vychýlení jsou inicializovány pomocí funkce tf.random.normal – tato funkce vytváří tenzory náhodných čísel, čerpaných z normálního rozdělení. Umožňuje vývojáři specifikovat věci, jako je standardní odchylka distribuce, ze které jsou náhodná čísla tažena.
Všimněte si tvaru proměnných. Proměnná W1 je tenzor [784, 300] – 784 uzlů je velikost vstupní vrstvy. Tato velikost pochází ze sloučení vstupních obrázků – máme-li 28 řádků a 28 sloupců pixelů, jejich sloučením získáme 1 řádek nebo sloupec o velikosti 28 x 28 = 784 hodnot. 300 v deklaraci W1 je počet uzlů ve skryté vrstvě. Proměnná W2 je tenzor [300, 10] spojující 300-uzlovou skrytou vrstvu s 10-uzlovou výstupní vrstvou. V každém případě je proměnné přidělen název pro pozdější zobrazení v TensorBoard – vizualizačním balíčku TensorFlow. Dalším krokem v kódu je vytvoření výpočtů, které probíhají v uzlech sítě. Pokud si čtenář pamatuje, výpočty v rámci uzlů neuronové sítě mají následující formu:
$$ z = Wx + b $$
Kde W je matice vah, x je vstupní vektor vrstvy, b je odchylka a f je aktivační funkce uzlu. Tyto výpočty zahrnují dopředný průchod vstupních dat neuronovou sítí. Pro provádění těchto výpočtů je vytvořena vyhrazená funkce dopředného přenosu:
def nn_model(x_input, W1, b1, W2, b2):
# flatten the input image from 28 x 28 to 784
x_input = tf.reshape(x_input, (x_input.shape[0], -1))
x = tf.add(tf.matmul(tf.cast(x_input, tf.float32), W1), b1)
x = tf.nn.relu(x)
logits = tf.add(tf.matmul(x, W2), b2)
return logitsPři zkoumání prvního řádku jsou data x_input přetvořena z (batch_size, 28, 28) na (batch_size, 784) – jinými slovy, obrázky jsou vyrovnány. Na dalším řádku jsou pak vstupní data převedena na typ tf.float32 pomocí funkce cast TensorFlow. To je důležité – data x_input přicházejí jako typ tf.float64 a TensorFlow neprovede operaci násobení matic ( tf.matmul) mezi tenzory různých datových typů. Tato přetypovaná vstupní data jsou poté maticově vynásobena W1 pomocí funkce TensorFlow matmul (což je zkratka pro maticové násobení). Pak zkreslení b1se k tomuto produktu přidává. Na následujícím řádku se na výstup tohoto řádku výpočtu aplikuje funkce aktivace ReLU. Funkce ReLU je obvykle nejlepší aktivační funkcí pro použití v hlubokém učení.
Výstup tohoto výpočtu se pak vynásobí konečnou sadou vah W2 s připočtenou odchylkou b2 . Výstup tohoto výpočtu je nazván logits. Všimněte si, že na tuto výstupní vrstvu uzlů nebyla (zatím) použita žádná aktivační funkce. Ve strojovém/hlubokém učení se termín „logits“ vztahuje k neaktivovanému výstupu vrstvy uzlů.
Důvodem, proč na tuto vrstvu nebyla aplikována žádná aktivační funkce, je to, že v TensorFlow existuje užitečná funkce nazvaná tf.nn.softmax_cross_entropy_with_logits . Tato funkce dělá pro vývojáře dvě věci – aplikuje na logity aktivační funkci softmax, která je transformuje na kvazi-pravděpodobnost (tj. součet výstupních uzlů je roven 1). Toto je běžná aktivační funkce, která se aplikuje na výstupní vrstvu v klasifikačních úlohách. Dále aplikuje funkci ztráty křížové entropie na aktivační výstup softmax. Funkce ztráty zkřížené entropie je běžně používaná ztráta v klasifikačních úlohách. Níže uvedený kód používá tuto užitečnou funkci TensorFlow a v tomto příkladu byla vnořena do jiné funkce nazvané loss_fn:
def loss_fn(logits, labels):
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=logits))
return cross_entropyArgumenty pro softmax_cross_entropy_with_logits jsou štítky a logity. Argument logits pochází z výsledku funkce nn_model . Využití této funkce v hlavní tréninkové smyčce bude zanedlouho ukázáno. Argument labels je dodáván z hodnot one-hot y, které jsou vkládány do loss_fn během tréninkového procesu. Výstup softmax_cross_entropy_with_logitsFunkce bude výstupem hodnoty ztráty křížové entropie pro každý vzorek v dávce. Aby bylo možné trénovat váhy neuronové sítě, je třeba v rámci optimalizačního procesu minimalizovat průměrnou ztrátu křížové entropie napříč vzorky. To se vypočítá pomocí funkce tf.reduce_mean, která nepřekvapivě vypočítá střední hodnotu dodaného tenzoru.
Dalším krokem je definování funkce optimalizace. V mnoha příkladech v této knize bude použit všestranný optimalizátor Adam . Teorie tohoto optimalizátoru je zajímavá a stojí za další prozkoumání (jako je uvedeno zde), ale v tomto příspěvku se jí nebudeme podrobně věnovat. Je to v podstatě metoda gradientního sestupu, ale se sofistikovaným průměrováním gradientů, aby poskytla vhodnou dynamiku učení. Chcete-li definovat optimalizátor, který bude použit v hlavní tréninkové smyčce, spustí se následující kód:
# setup the optimizer
optimizer = tf.keras.optimizers.Adam()Objekt Adam může mít jako vstup rychlost učení, ale pro současné účely se používá výchozí hodnota.
3.1 Učení sítě
Nyní, když byly vytvořeny příslušné funkce, proměnné a optimalizátory, je čas definovat celkovou tréninkovou smyčku. Tréninková smyčka je zobrazena níže:
total_batch = int(len(y_train) / batch_size)
for epoch in range(epochs):
avg_loss = 0
for i in range(total_batch):
batch_x, batch_y = get_batch(x_train, y_train, batch_size=batch_size)
# create tensors
batch_x = tf.Variable(batch_x)
batch_y = tf.Variable(batch_y)
# create a one hot vector
batch_y = tf.one_hot(batch_y, 10)
with tf.GradientTape() as tape:
logits = nn_model(batch_x, W1, b1, W2, b2)
loss = loss_fn(logits, batch_y)
gradients = tape.gradient(loss, [W1, b1, W2, b2])
optimizer.apply_gradients(zip(gradients, [W1, b1, W2, b2]))
avg_loss += loss / total_batch
test_logits = nn_model(x_test, W1, b1, W2, b2)
max_idxs = tf.argmax(test_logits, axis=1)
test_acc = np.sum(max_idxs.numpy() == y_test) / len(y_test)
print(f"Epoch: {epoch + 1}, loss={avg_loss:.3f}, test set accuracy={test_acc*100:.3f}%")
print("\nTraining complete!")Procházíme-li řádky výše, první řádek je výpočtem k určení počtu dávek, které se mají projít v každé epoše učení – to zajistí, že v průměru bude každý trénovací vzorek v dané epoše použit jednou. Poté se zadá smyčka pro každou tréninkovou epochu. Proměnná avg_cost je inicializována, aby sledovala průměrné náklady/ztráty křížové entropie pro každou epochu. Na dalším řádku jsou extrahovány náhodné dávky vzorků (batch_x a batch_y) z trénovací datové sady MNIST pomocí funkce get_batch() , která byla vytvořena dříve.
Dále jsou numpy proměnné batch_x a batch_y převedeny na proměnné tenzoru. Poté je třeba data štítku uložená v batch_y jako jednoduchá celá čísla (tj. 2 pro ručně psanou číslici „2“ a tak dále) převést do formátu „one hot“, jak bylo uvedeno výše. K tomu lze využít funkci tf.one_hot – prvním argumentem této funkce je tenzor, který chcete převést, a druhým argumentem je počet odlišných tříd. Tím se transformuje tenzor batch_y z velikosti (velikost_dávky, 1) na (velikost_dávky, 10).
Důležitý je další řádek. Zde je představeno rozhraní API TensorFlow GradientTape . V předchozích verzích TensorFlow byl vytvořen statický graf všech operací a proměnných. V tomto paradigmatu lze gradienty, které bylo třeba vypočítat, určit čtením ze struktury grafu. V režimu Eager se však všechny výpočty tenzorů provádějí za běhu a TensorFlow neví, pro které proměnné a operace máte zájem počítat gradienty. Řešením je rozhraní Gradient Tape API. Jakékoli proměnné a operace, které si přejete vypočítat gradienty, dodáte pomocí GradientTape() jako pásku:“kontextový manažer. V neuronové síti to zahrnuje všechny proměnné a operace zahrnuté v dopředném průchodu vaší sítí spolu s vyhodnocením ztrátové funkce. Všimněte si, že pokud zavoláte funkci v kontextu pásky s přechodem, všechny operace provedené v rámci této funkce (a jakékoli další vnořené funkce) budou podle potřeby zachyceny pro výpočet přechodu.
Jak lze pozorovat v kódu výše, dopředný průchod a vyhodnocení ztrátové funkce jsou zapouzdřeny ve funkcích, které byly vysvětleny dříve: nn_model a loss_fn . Spuštěním těchto funkcí v rámci kontextového manažeru pásky s přechodem TensorFlow ví, že má sledovat všechny proměnné a výsledky operací, aby bylo zajištěno, že jsou připraveny na výpočty gradientu. Po volání funkcí nn_model a loss_fn v kontextu gradientní pásky máme místo, kde se počítají gradienty neuronové sítě.
Zde se k pásce s přechodem přistupuje přes její název ( v tomto příkladu páska ) a funkce přechodu se nazývá tape.gradient() . První argument této funkce je závislá proměnná derivace a druhý argument je nezávislá proměnná/y. Jinými slovy, pokud bychom se snažili vypočítat derivaci dy/dx, první argument by byl y a druhý by byl x pro tuto funkci. V kontextu neuronové sítě se snažíme vypočítat dL/dw a dL/db , kde L je ztráta, w představuje váhy a bváhy předpětí spojů. Proto ve výše uvedeném kódu může čtenář pozorovat, že první argument je ztrátový výstup z loss_fn a druhý argument je seznam všech váhových a zkreslených proměnných v celé jednoduché neuronové síti.
Další řádek je místo, kde jsou tyto gradienty spojeny s proměnnými hmotnosti a zkreslení a předány optimalizátoru, aby provedl krok sestupu gradientu. To lze snadno provést pomocí funkce apply_gradients() optimalizátoru .
Následující čára je akumulací průměrné ztráty v rámci epochy. Toto tvoří vnitřní epochovou tréninkovou smyčku. V tréninkové smyčce vnější epochy se po každé epoše tréninku vyhodnocuje přesnost modelu na testovací sadě.
K určení přesnosti nejprve projdou obrázky testovací sady modelem neuronové sítě pomocí nn_model . Tím se vrátí logity z modelu (neaktivované výstupy z poslední vrstvy). Z těchto logitů se pak vypočítá „predikce“ modelu – kterýkoli výstupní uzel má nejvyšší hodnotu logitů, jedná se o číselnou predikci modelu. K určení nejvyšší hodnoty logit pro každý testovací obrázek můžeme použít funkci tf.argmax() . Tato funkce napodobuje numpy argmax()funkce, která vrací index nejvyšší hodnoty v poli/tensoru. Výstup logitů z modelu v tomto případě bude mít následující rozměry: (test_set_size, 10) – chceme, aby funkce argmax našla maximum v každém z rozměrů „sloupce“, tj. napříč 10 výstupními uzly. Rozměr „řádek“ odpovídá axis=0 a rozměr sloupce odpovídá axis=1. Proto zadání argumentu axis=1 do funkce tf.argmax() vytvoří (test_set_size, 1) celočíselné predikce.
Na následujícím řádku jsou tyto max_idx převedeny na numpy pole (pomocí .numpy()) a potvrzeno, že se rovnají testovacím štítkům (také celým číslům – jistě si vzpomenete, že jsme nepřevedli testovací štítky do jednoho horkého formátu). Pokud jsou štítky stejné, vrátí hodnotu „true“, která je ekvivalentní celému číslu 1 v numpy, nebo alternativně hodnotu „false“ / 0. Sečtením výsledků těchto tvrzení získáme počet správných předpovědí. Vydělíme-li to celkovou velikostí testovací sady, získáme přesnost testovací sady.
Poznámka: Pokud některá z těchto vysvětlení nejsou okamžitě jasná, je dobré přejít na kód dodaný pro tuto kapitolu a spustit jej ve standardním vývojovém prostředí Pythonu. Vložte bod přerušení do kódu, který chcete prozkoumat blíže – pak můžete zkontrolovat všechny velikosti tenzorů, převést je na numpy pole, aplikovat operace za běhu a tak dále. To vše je nyní možné v rámci TensorFlow 2, když je výchozím provozním paradigmatem Eager provádění.
Číslo epochy, průměrná ztráta a přesnost jsou pak vytištěny, takže je možné sledovat průběh tréninku. Průměrná ztráta by se měla po každé epoše v průměru snižovat – pokud tomu tak není, je se sítí něco v nepořádku nebo učení stagnuje. Proto je důležitou proměnnou, kterou je třeba sledovat. Při spuštění tohoto kódu by mělo být pozorováno něco jako následující výstup:
Epocha: 1, cena=0,317, přesnost testovací sady=94,350 %
Epocha: 2, cena=0,124, přesnost testovací sady=95,940 %
Epocha: 3, cena=0,085, přesnost testovací sady=97,070 %
Epocha: 4, cena=0,065, přesnost testovací sady=97,570 %
Epocha: 5, cena=0,052, přesnost testovací sady=97,630 %
Epocha: 6, cena=0,048, přesnost testovací sady=97,620 %
Epocha: 7, cena=0,037, přesnost testovací sady=97,770 %
Epocha: 8, cena=0,032, přesnost testovací sady=97,630 %
Epocha: 9, cena=0,027, přesnost testovací sady=97,950 %
Epocha: 10, cena=0,022, přesnost testovací sady=98,000 %
Training complete!
Jak lze pozorovat, ztráta monotónně klesá a přesnost testovací sady se neustále zvyšuje. To ukazuje, že model trénuje správně. Je také možné vizualizovat průběh tréninku pomocí TensorBoard, jak je znázorněno níže:
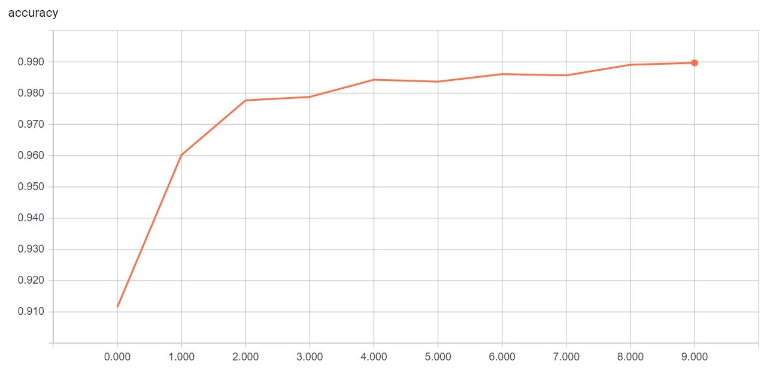
TensorBoard graf nárůstu přesnosti za 10 epoch
import tensorflow as tf
import numpy as np
import datetime as dt
from tensorflow.keras.datasets import mnist
STORE_PATH = '/Users/TensorBoard'
def run_simple_graph():
# create TensorFlow variables
const = tf.Variable(2.0, name="const")
b = tf.Variable(2.0, name='b')
c = tf.Variable(1.0, name='c')
# now create some operations
d = tf.add(b, c, name='d')
e = tf.add(c, const, name='e')
a = tf.multiply(d, e, name='a')
# alternatively (and more naturally)
d = b + c
e = c + 2
a = d * e
print(f"Variable a is {a.numpy()}")
def run_simple_graph_multiple():
const = tf.Variable(2.0, name="const")
b = tf.Variable(np.arange(0, 10), name='b')
c = tf.Variable(1.0, name='c')
d = tf.cast(b, tf.float32) + c
e = c + const
a = d * e
print(f"Variable a is {a.numpy()}")
# the line below would cause an error - tensors are immutable
# b[1] = 10
# need to use assignment instead
b[1].assign(10)
d = tf.cast(b, tf.float32) + c
e = c + const
a = d * e
print(f"Variable a is {a.numpy()}")
b[6:9].assign([10, 10, 10])
f = b[2:5]
print(f.numpy())
def get_batch(x_data, y_data, batch_size):
idxs = np.random.randint(0, len(y_data), batch_size)
return x_data[idxs,:,:], y_data[idxs]
def nn_model(x_input, W1, b1, W2, b2):
# flatten the input image from 28 x 28 to 784
x_input = tf.reshape(x_input, (x_input.shape[0], -1))
x = tf.add(tf.matmul(tf.cast(x_input, tf.float32), W1), b1)
x = tf.nn.relu(x)
logits = tf.add(tf.matmul(x, W2), b2)
return logits
def loss_fn(logits, labels):
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=labels,
logits=logits))
return cross_entropy
def nn_example():
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Python optimisation variables
epochs = 10
batch_size = 100
# normalize the input images by dividing by 255.0
x_train = x_train / 255.0
x_test = x_test / 255.0
# convert x_test to tensor to pass through model (train data will be converted to
# tensors on the fly)
x_test = tf.Variable(x_test)
# now declare the weights connecting the input to the hidden layer
W1 = tf.Variable(tf.random.normal([784, 300], stddev=0.03), name='W1')
b1 = tf.Variable(tf.random.normal([300]), name='b1')
# and the weights connecting the hidden layer to the output layer
W2 = tf.Variable(tf.random.normal([300, 10], stddev=0.03), name='W2')
b2 = tf.Variable(tf.random.normal([10]), name='b2')
# setup the optimizer
optimizer = tf.keras.optimizers.Adam()
# create a summary writer to view loss in TensorBoard
train_summary_writer = tf.summary.create_file_writer(STORE_PATH +
"/TensorFlow_Intro_Chapter_" +
f"{dt.datetime.now().strftime('%d%m%Y%H%M')}")
total_batch = int(len(y_train) / batch_size)
for epoch in range(epochs):
avg_loss = 0
for i in range(total_batch):
batch_x, batch_y = get_batch(x_train, y_train, batch_size=batch_size)
# create tensors
batch_x = tf.Variable(batch_x)
batch_y = tf.Variable(batch_y)
# create a one hot vector
batch_y = tf.one_hot(batch_y, 10)
with tf.GradientTape() as tape:
logits = nn_model(batch_x, W1, b1, W2, b2)
loss = loss_fn(logits, batch_y)
gradients = tape.gradient(loss, [W1, b1, W2, b2])
optimizer.apply_gradients(zip(gradients, [W1, b1, W2, b2]))
avg_loss += loss / total_batch
test_logits = nn_model(x_test, W1, b1, W2, b2)
max_idxs = tf.argmax(test_logits, axis=1)
test_acc = np.sum(max_idxs.numpy() == y_test) / len(y_test)
print(f"Epoch: {epoch + 1}, loss={avg_loss:.3f}, test set accuracy={test_acc*100:.3f}%")
with train_summary_writer.as_default():
tf.summary.scalar('loss', avg_loss, step=epoch)
tf.summary.scalar('accuracy', test_acc, step=epoch)
print("\nTraining complete!")
if __name__ == "__main__":
# run_simple_graph()
# run_simple_graph_multiple()
nn_example()
Literatura
Python TensorFlow Tutorial – Build a Neural Network. Adventures in Machine Learning [online]. 2020 [cit. 2022-12-15]. Dostupné z: https://adventuresinmachinelearning.com/python-tensorflow-tutorial/