Tutoriál Keras ukáže, jak vytvořit CNN pro dosažení > 99% přesnosti s datovou sadou MNIST.
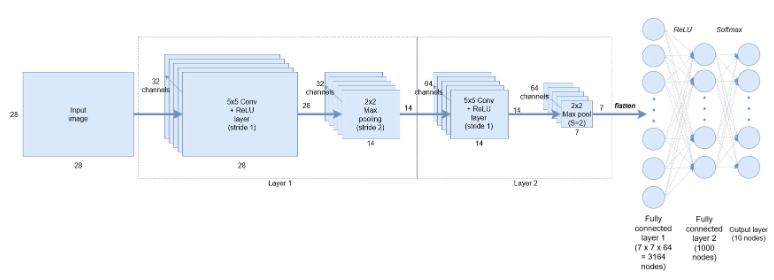
Konvoluční neuronová síť, která bude vybudována
Hlavní kód v tomto tutoriálu Keras
Níže uvedený kód je „vnitřnostmi“ struktury CNN, která bude použita v tomto tutoriálu Keras:
model = Sequential()
model.add(Conv2D(32, kernel_size=(5, 5), strides=(1, 1),
activation=’relu’,
input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Conv2D(64, (5, 5), activation=’relu’))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(1000, activation=’relu’))
model.add(Dense(num_classes, activation=’softmax’))Postupně projdeme většinu řádků a vysvětlíme je za pochodu.
model = Sequential()Modely v Kerasu mohou přijít ve dvou formách – sekvenční a přes funkční API. Pro většinu sítí hlubokého učení, které vytváříte, pravděpodobně použijete sekvenční model. Umožňuje snadno skládat sekvenční vrstvy (a dokonce i opakující se vrstvy) sítě v pořadí od vstupu k výstupu. Funkční rozhraní API vám umožňuje vytvářet složitější architektury a v tomto tutoriálu se jím nebudeme zabývat.
První řádek deklaruje typ modelu jako Sequential().
model.add(Conv2D(32, kernel_size=(5, 5), strides=(1, 1),
activation=’relu’,
input_shape=input_shape))Dále přidáme 2D konvoluční vrstvu pro zpracování 2D vstupních obrazů MNIST. První argument předaný funkci vrstvy Conv2D() je počet výstupních kanálů – v tomto případě máme 32 výstupních kanálů (podle architektury zobrazené na začátku). Dalším vstupem je kernel_size, což jsme v tomto případě zvolili jako pohyblivé okno 5×5 následované kroky ve směru x a y (1, 1). Dále je aktivační funkcí rektifikovaná lineární jednotka a nakonec musíme modelu dodat velikost vstupu do vrstvy. Deklarování vstupního tvaru je vyžadováno pouze u první vrstvy – Keras je dost dobrý na to, aby odtamtud vypočítal velikost tenzorů proudících modelem.
Všimněte si také, že nemusíme deklarovat žádné váhy nebo proměnné zkreslení, jako to děláme v TensorFlow, Keras to za nás vyřeší.
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))Dále přidáme sdružovací vrstvu 2D max. Definice vrstvy je smrtelně snadná. Jednoduše určíme velikost sdružování ve směrech x a y – v tomto případě (2, 2) a kroky. A je to.
model.add(Conv2D(64, (5, 5), activation=’relu’))
model.add(MaxPooling2D(pool_size=(2, 2)))Dále přidáme další konvoluční + maximální sdružovací vrstvu s 64 výstupními kanály. Výchozí argument strides ve funkci Conv2D() je v Kerasu (1, 1), takže jej můžeme vynechat. Výchozí argument kroků v Kerasu je, aby se rovnal velikosti fondu, takže jej opět můžeme vynechat.
Vstupní tenzor pro tuto vrstvu je (batch_size, 28, 28, 32) – 28 x 28 je velikost obrázku a 32 je počet výstupních kanálů z předchozí vrstvy. Všimněte si však, že nemusíme výslovně uvádět, jaký je tvar vstupu – Keras to vyřeší za nás. To umožňuje rychlé sestavení síťových architektur, aniž byste se museli příliš starat o velikosti tenzorů proudících kolem našich sítí.
model.add(Flatten())
model.add(Dense(1000, activation=’relu’))
model.add(Dense(num_classes, activation=’softmax’))Nyní, když jsme vytvořili naše konvoluční vrstvy, chceme zploštit výstup z nich, aby vstoupily do našich plně propojených vrstev. V TensorFlow jsme museli zjistit, jaká je velikost našeho výstupního tenzoru z konvolučních vrstev, abychom jej mohli zploštit a také explicitně určit velikost našich proměnných hmotnosti a zkreslení. Jistě, není to příliš obtížné – ale jen nám to usnadňuje život, když na to nemusíme příliš myslet.
Následující dva řádky deklarují naše plně propojené vrstvy – pomocí vrstvy Dense() v Kerasu. Opět je to velmi jednoduché. Nejprve určíme velikost – v souladu s naší architekturou zadáme 1000 uzlů, každý aktivovaný funkcí ReLU. Druhou je naše soft-max klasifikace, neboli výstupní vrstva, což je velikost počtu našich tříd (10 v tomto případě pro našich 10 možných ručně psaných číslic).
To je vše – úspěšně jsme vyvinuli architekturu naší CNN v pouhých 8 řádcích. Nyní se podívejme, co musíme udělat pro trénování modelu a provádění předpovědí.
Učení a vyhodnocení konvoluční neuronové sítě
Nyní jsme vyvinuli architekturu CNN v Kerasu, ale nespecifikovali jsme ztrátovou funkci, ani jsme neřekli frameworku, jaký typ optimalizátoru použít (tj . gradientní sestup, Adam optimalizátor atd.). V Keras to lze provést jedním příkazem:
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.SGD(lr=0.01),
metrics=[’accuracy’])Keras dodává mnoho ztrátových funkcí (nebo si můžete vytvořit vlastní), jak můžete vidět zde . V tomto případě použijeme standardní křížovou entropii pro klasifikaci kategorických tříd (keras.losses.categorical_crossentropy). Keras dodává také mnoho optimalizátorů – jak je vidět zde. V tomto případě použijeme optimalizátor Adam (keras.optimizers.Adam) stejně jako v tutoriálu CNN TensorFlow . Nakonec můžeme určit metriku, která se vypočítá, když na modelu spustíme value(). V TensorFlow bychom museli definovat operaci výpočtu přesnosti, kterou bychom museli volat, abychom mohli posoudit přesnost. V tomto případě nám to Keras usnadňuje. Zde naleznete seznam metrik, které lze použít.
Dále chceme trénovat náš model. To lze provést opětovným spuštěním jediného příkazu v Keras:
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test),
callbacks=[history])Tento příkaz vypadá podobně jako syntaxe používaná ve velmi oblíbené knihovně strojového učení scikit learn Pythonu. Nejprve předáme všechna naše tréninková data – v tomto případě x_train a y_train . Dalším argumentem je velikost dávky – nemusíme explicitně řešit dávkování našich dat během trénování v Kerasu, spíše jen určíme velikost dávky a udělá to za nás (mám příspěvek o mini-dávkovém gradientu klesánípokud je vám to neznámé). V tomto případě používáme velikost dávky 128. Dále předáme počet epoch tréninku (v tomto případě 10). Podrobný příznak, zde nastavený na 1, určuje, zda chcete, aby se v konzole tiskly podrobné informace o průběhu školení. Pokud je během trénování verbose nastaveno na 1, do konzole se odešle následující:
3328/60000 [>………………………..] - ETA: 87s - loss: 0.2180 - acc: 0.9336
3456/60000 [>………………………..] - ETA: 87s - loss: 0.2158 - acc: 0.9349
3584/60000 [>………………………..] - ETA: 87s - loss: 0.2145 - acc: 0.9350
3712/60000 [>………………………..] - ETA: 86s - loss: 0.2150 - acc: 0.9348Nakonec předáme ověřovací nebo testovací data do funkce fit, takže Keras ví, proti jakým datům má testovat metriku, když je na modelu spuštěna funkce cancel(). V tuto chvíli ignorujte argument zpětných volání – o tom bude brzy řeč.
Jakmile je model natrénován, můžeme jej vyhodnotit a vytisknout výsledky:
score = model.evaluate(x_test, y_test, verbose=0)
print(‘Test loss:’, score[0])
print(‘Test accuracy:’, score[1])Po 10 epochách trénování výše uvedeného modelu dosáhneme přesnosti 99,2 %, což je stejné, jako jsme dosáhli v TensorFlow pro stejnou síť. Zlepšení přesnosti pro každou epochu můžete vidět na obrázku níže:
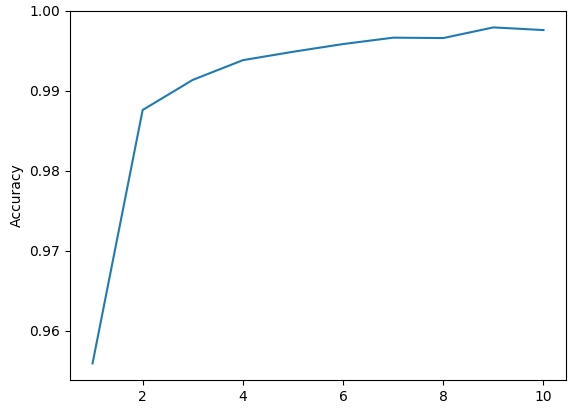
Přesnost tréninku Keras CNN MNIST
Keras věci docela usnadňuje, nemyslíte? Doufám, že tento tutoriál Keras ukázal, jak může být užitečným rámcem pro rychlé prototypování řešení hlubokého učení.
Jako jakousi přílohu vám ukážu, jak sledovat přesnost, když procházíme tréninkovými epochami, což mi umožnilo vygenerovat výše uvedený graf.
Protokolování metrik v Keras
Keras má užitečnou utilitu s názvem „zpětná volání“, kterou lze využít ke sledování nejrůznějších proměnných během tréninku. Můžete jej také použít k vytvoření kontrolních bodů, které uloží model v různých fázích školení, abyste se vyhnuli ztrátě práce v případě, že se váš nebohý přetížený počítač rozhodne havarovat. Je předán do funkce .fit(), jak je uvedeno výše. Níže vám ukážu pouze poměrně jednoduchý případ použití, který zaznamenává přesnost.
Pro vytvoření zpětného volání vytvoříme zděděnou třídu, která dědí z keras.callbacks.Callback:
class AccuracyHistory(keras.callbacks.Callback):
def on_train_begin(self, logs={}):
self.acc = []
def on_epoch_end(self, batch, logs={}):
self.acc.append(logs.get(‘acc’))Nadtřída Callback, ze které výše uvedený kód dědí, má řadu metod, které lze v naší definici zpětného volání přepsat, například on_train_begin, on_epoch_end, on_batch_begin a on_batch_end. Názvy těchto metod jsou poměrně samozřejmé a představují momenty v tréninkovém procesu, kde můžeme „dělat věci“. Ve výše uvedeném kódu na začátku tréninku inicializujeme seznam self.acc = [] , abychom uložili naše výsledky přesnosti. Pomocí metody on_epoch_end () můžeme z protokolů extrahovat požadovanou proměnnou, což je slovník, který jako výchozí uchovává ztráty a přesnost během tréninku. Toto zpětné volání pak vytvoříme takto:
history = AccuracyHistory()Nyní můžeme předat historii funkci .fit() pomocí názvu parametru callback. Všimněte si, že .fit() bere seznam pro parametr zpětného volání , takže mu musíte předat historii takto: [historie]. Chcete-li získat přístup k seznamu přesnosti, který jsme vytvořili po dokončení školení, můžete jednoduše zavolat history.acc, který jsem pak také vykreslil:
plt.plot(range(1,11), history.acc)
plt.xlabel(‘Epochs’)
plt.ylabel(‘Accuracy’)
plt.show()To je vše. Níže je uveden kompletní kód v Pythonu.
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.layers import Dense, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.models import Sequential
import matplotlib.pylab as plt
batch_size = 128
num_classes = 10
epochs = 10
# input image dimensions
img_x, img_y = 28, 28
# load the MNIST data set, which already splits into train and test sets for us
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# reshape the data into a 4D tensor - (sample_number, x_img_size, y_img_size, num_channels)
# because the MNIST is greyscale, we only have a single channel - RGB colour images would have 3
x_train = x_train.reshape(x_train.shape[0], img_x, img_y, 1)
x_test = x_test.reshape(x_test.shape[0], img_x, img_y, 1)
input_shape = (img_x, img_y, 1)
# convert the data to the right type
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices - this is for use in the
# categorical_crossentropy loss below
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
model = Sequential()
model.add(Conv2D(32, kernel_size=(5, 5), strides=(1, 1),
activation='relu',
input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Conv2D(64, (5, 5), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(1000, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adam(),
metrics=['accuracy'])
class AccuracyHistory(keras.callbacks.Callback):
def on_train_begin(self, logs={}):
self.acc = []
def on_epoch_end(self, batch, logs={}):
self.acc.append(logs.get('acc'))
history = AccuracyHistory()
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test),
callbacks=[history])
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
plt.plot(range(1, 11), history.acc)
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.show()